










Any Learning Management System can host courses—only Skilljar transforms them into polished and personalized experiences that drive onboarding and adoption. With our suite of integrations and monetization tools, your Academy’s business impact is crystal clear.

Draw customers in with easy, engaging learning. Skilljar turns education into a breeze, speeding up onboarding, and keeping customers coming back.
From quick tips to live sessions, Skilljar makes training dynamic with personalized paths and certifications, inspiring discovery.
Monetize effortlessly with flexible pricing options for courses, paths, subscriptions, or credits, using our payments and Salesforce integrations.
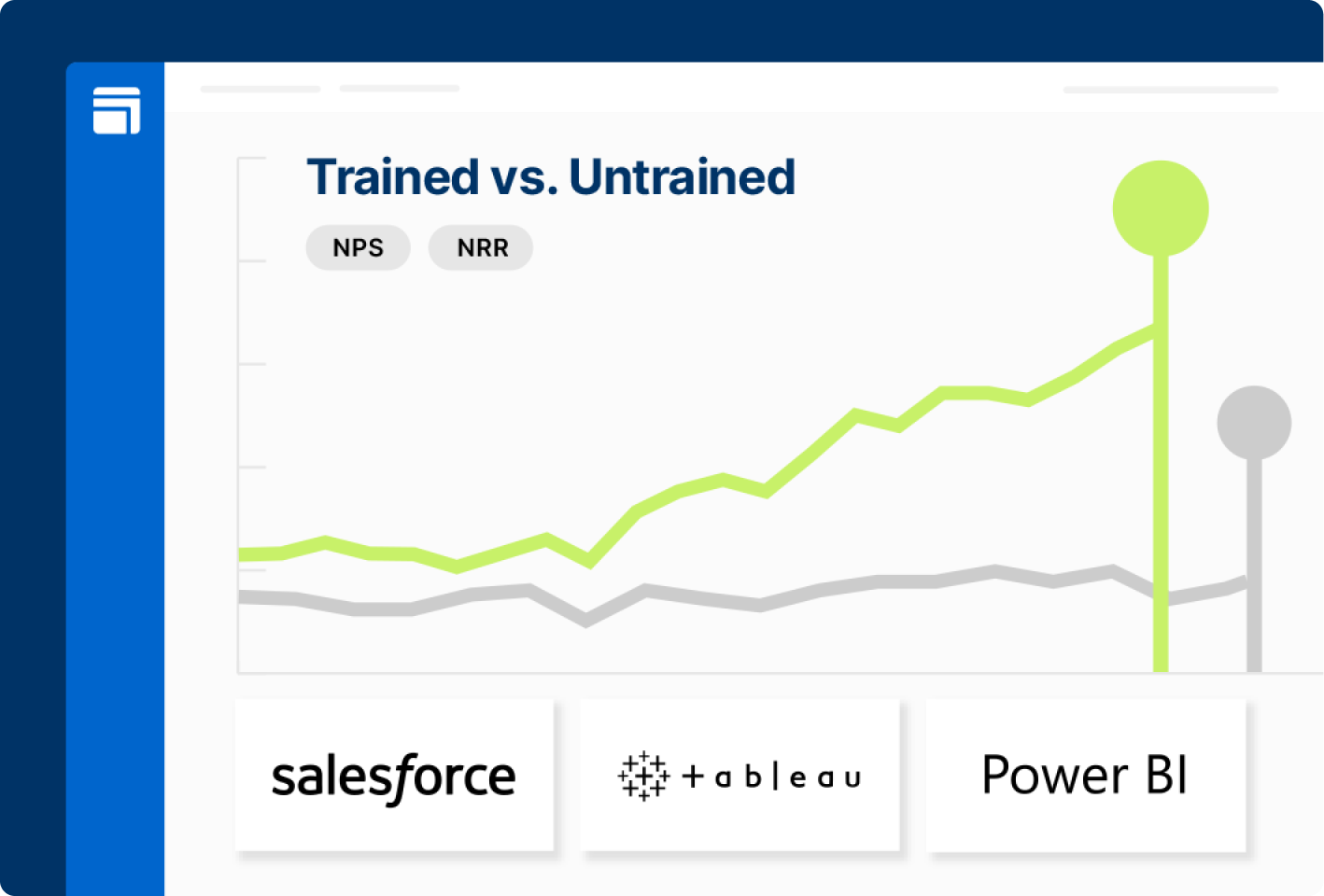
Transition from tactics to tangible results, leveraging analytics and Salesforce to link training with NPS, adoption, and customer retention.
See how real companies deliver scalable customer learning programs with Skilljar.
After a decade in customer education, we’ve learned that one-to-one training doesn't scale and how-to videos alone don’t work. Here’s what our customers do instead.



